import osimport sys"../../../" )import jsonimport pickleimport fasttreeshapimport numpy as npimport pandas as pdimport shapfrom sklearn.model_selection import RepeatedKFold, cross_val_score% reload_ext autoreload% autoreload 2
IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
Load Training Data
= "ph" = "-" .join(os.getcwd().split("/" )[- 2 ].split("-" )[:3 ])# CSV file contains all data # Metadata JSON file lists the feature columns and label column = pd.read_csv(f" { ROLLOUT_DATE} -training-data.csv" )with open (f" { ROLLOUT_DATE} -training-data-columns.json" , "r" ) as file := json.load(file )= data[column_metadata["features" ]]= data[column_metadata["label" ]]
Cross-Validation
# Set parameters = 5 = 5 = 42
print (f"Performing { CV_K_FOLDS} -fold CV..." )= RepeatedKFold(= CV_K_FOLDS,= CV_NUM_REPEATS,= RANDOM_SEED,print (cv.split(features))
Performing 5-fold CV...
<generator object _RepeatedSplits.split at 0x7ff647383970>
from sklearn.ensemble import RandomForestRegressor= RandomForestRegressor(n_estimators= 100 , random_state= RANDOM_SEED, verbose= 0 )= cross_val_score(model, features.values, labels.values.ravel(), cv= cv)= round (np.array(R_cv).mean(), 2 )= round (np.array(R_cv).std(), 2 )print ("Cross validation scores are: " , R_cv)print (f"Cross validation R^2 mean: { cv_mean} " )print (f"Cross validation R^2 std: { cv_std} " )
Cross validation scores are: [0.55682521 0.63091503 0.59480566 0.61487913 0.58103858 0.58468717
0.6176015 0.55499181 0.56994707 0.63015257 0.64765313 0.61932703
0.59837317 0.54697645 0.54584293 0.53601267 0.59513112 0.6302872
0.55665255 0.59870962 0.58082884 0.5416791 0.62810948 0.63953924
0.5935612 ]
Cross validation R^2 mean: 0.59
Cross validation R^2 std: 0.03
Train the final model
For training the final model, we train on all the available data.
= RandomForestRegressor(n_estimators= 100 , random_state= RANDOM_SEED, verbose= 0 )
RandomForestRegressor(random_state=42) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
= f"./ { ROLLOUT_DATE} - { COUNTRY_CODE} -single-country-model.pkl" with open (model_save_path, "wb" ) as file :file )
SHAP
= fasttreeshap.TreeExplainer(model, algorithm= "auto" , n_jobs=- 1 )= explainer(features).values
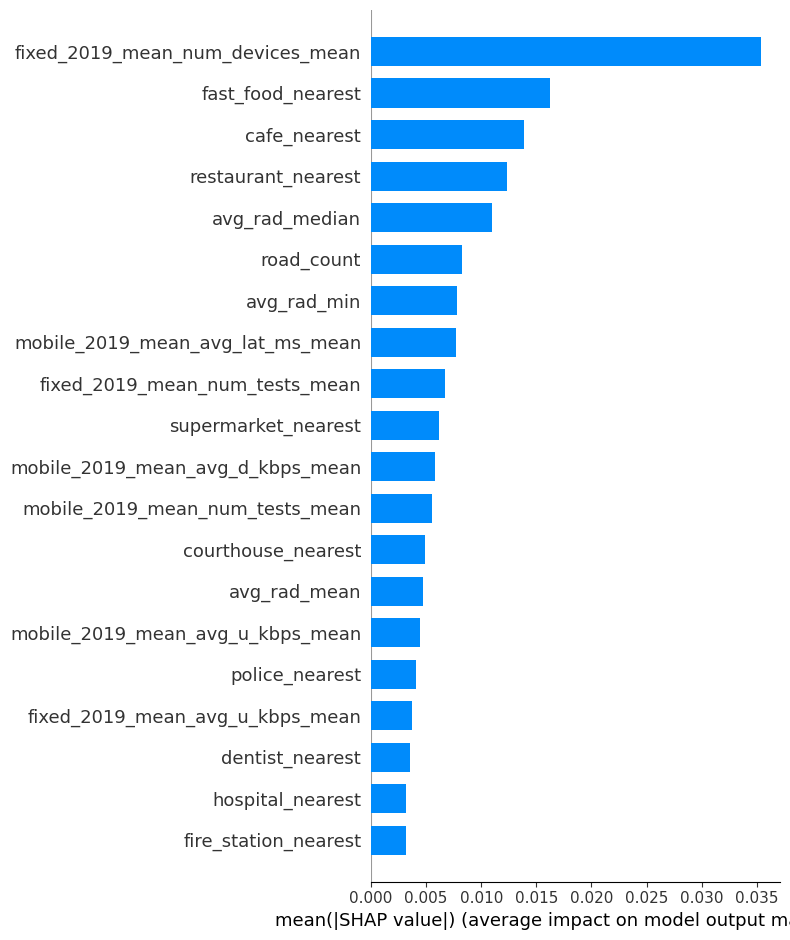
= features.columns, plot_type= "bar"
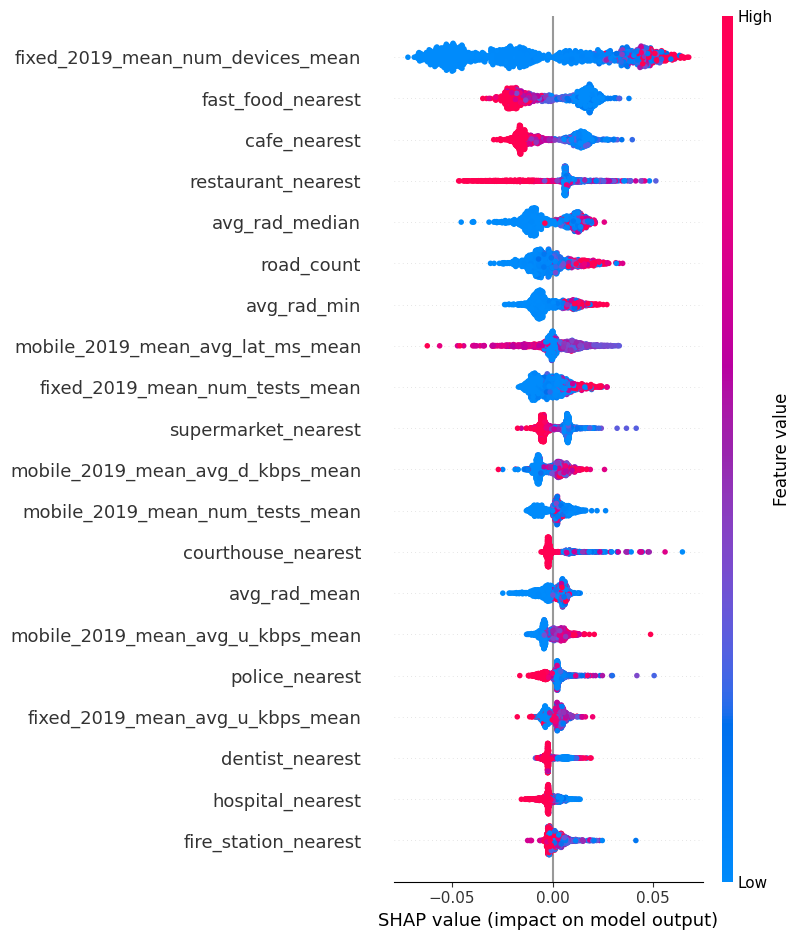
= features.columns)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored