%matplotlib inline
%reload_ext autoreload
%autoreload 2Predict on rollout grids
import os
import sys
sys.path.append("../../../")
import getpass
import pickle
from pathlib import Path
import contextily as cx
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from povertymapping import nightlights, settings
from povertymapping.dhs import generate_dhs_cluster_level_data
from povertymapping.feature_engineering import (
categorize_wealth_index,
generate_features,
)
from povertymapping.iso3 import get_region_name
from povertymapping.rollout_grids import get_region_filtered_bingtile_grids/home/jace/workspace/unicef-ai4d-poverty-mapping/env/lib/python3.9/site-packages/geopandas/_compat.py:111: UserWarning: The Shapely GEOS version (3.11.1-CAPI-1.17.1) is incompatible with the GEOS version PyGEOS was compiled with (3.10.1-CAPI-1.16.0). Conversions between both will be slow.
warnings.warn(Model Prediction on Rollout Grids: Laos
This notebook is the final step in the rollout and runs the final model to create relative wealth estimations over populated areas within the given country. The model predictions will have a spatial resolution of 2.4km.
The predicted relative wealth value gives us the relative wealth level of an area compared to the rest of the country, which fixes the value range from 0 (lowest wealth) to 1 (highest wealth). In between these extremes, each area’s wealth estimate is scaled to a value between 0 and 1.
The predicted relative wealth value is later binned into 5 wealth categories A-E by dividing the distribution into quintiles (every 20th percentile).
Set up Data Access
The following cell will prompt you to enter your EOG username and password. See this page to learn how to set-up your EOG account.
# Log-in using EOG credentials
username = os.environ.get("EOG_USER", None)
username = username if username is not None else input("Username?")
password = os.environ.get("EOG_PASSWORD", None)
password = password if password is not None else getpass.getpass("Password?")
# set save_token to True so that access token gets stored in ~/.eog_creds/eog_access_token
access_token = nightlights.get_eog_access_token(username, password, save_token=True)Set country-specific parameters
COUNTRY_CODE = "la"
COUNTRY_OSM = get_region_name(COUNTRY_CODE, code="alpha-2").lower()
OOKLA_YEAR = 2019
NIGHTLIGHTS_YEAR = 2017
rollout_date = "-".join(os.getcwd().split("/")[-2].split("-")[:3])
rollout_grids_path = Path(f"./{rollout_date}-{COUNTRY_CODE}-rollout-grids.geojson")
rollout_grids_pathPath('2023-02-21-la-rollout-grids.geojson')Set Model Parameters
# Model to use for prediction
MODEL_SAVE_PATH = Path(f"../{rollout_date}-cross-country-model.pkl")Load Country Rollout AOI
The rollout area of interest is split into 2.4km grid tiles (zoom level 14), matching the areas used during model training. The grids are also filtered to only include populated areas based on Meta’s High Resolution Settlement Layer (HRSL) data.
Refer to the previous notebook 2_la_generate_grids.ipynb for documentation on generating this grid.
aoi = gpd.read_file(rollout_grids_path)
aoi.info()Generate Features For Rollout AOI
If this is your first time running this notebook for this specific area, expect a long runtime for the following cell as it will download and cache the required datasets. It will then process the relevant features for each area specified. On subsequent runs, the runtime will be much faster as the data is already stored in your filesystem.
%%time
scaler = MinMaxScaler
rollout_aoi = aoi.copy()
# Create features dataframe using generate_features module
features = generate_features(
rollout_aoi,
country_osm=COUNTRY_OSM,
ookla_year=OOKLA_YEAR,
nightlights_year=NIGHTLIGHTS_YEAR,
scaled_only=False,
sklearn_scaler=scaler,
features_only=True,
use_aoi_quadkey=True,
)2023-04-03 08:12:16.563 | INFO | povertymapping.osm:download_osm_country_data:199 - OSM Data: Cached data available for laos at /home/jace/.geowrangler/osm/laos? True
2023-04-03 08:12:16.563 | DEBUG | povertymapping.osm:load_pois:161 - OSM POIs for laos being loaded from /home/jace/.geowrangler/osm/laos/gis_osm_pois_free_1.shp
2023-04-03 08:12:21.088 | INFO | povertymapping.osm:download_osm_country_data:199 - OSM Data: Cached data available for laos at /home/jace/.geowrangler/osm/laos? True
2023-04-03 08:12:21.090 | DEBUG | povertymapping.osm:load_roads:180 - OSM Roads for laos being loaded from /home/jace/.geowrangler/osm/laos/gis_osm_roads_free_1.shp
2023-04-03 08:12:26.487 | DEBUG | povertymapping.ookla:load_type_year_data:79 - Contents of data cache: []
2023-04-03 08:12:26.488 | INFO | povertymapping.ookla:load_type_year_data:94 - Cached data available at /home/jace/.geowrangler/ookla/processed/63e5da2e8a7b57f0ef7942656eb89e11.csv? True
2023-04-03 08:12:26.489 | DEBUG | povertymapping.ookla:load_type_year_data:99 - Processed Ookla data for aoi, fixed 2019 (key: 63e5da2e8a7b57f0ef7942656eb89e11) found in filesystem. Loading in cache.
2023-04-03 08:12:27.163 | DEBUG | povertymapping.ookla:load_type_year_data:79 - Contents of data cache: ['63e5da2e8a7b57f0ef7942656eb89e11']
2023-04-03 08:12:27.165 | INFO | povertymapping.ookla:load_type_year_data:94 - Cached data available at /home/jace/.geowrangler/ookla/processed/a1bc2e352417533b160e37996521193d.csv? True
2023-04-03 08:12:27.166 | DEBUG | povertymapping.ookla:load_type_year_data:99 - Processed Ookla data for aoi, mobile 2019 (key: a1bc2e352417533b160e37996521193d) found in filesystem. Loading in cache.
2023-04-03 08:12:28.109 | INFO | povertymapping.nightlights:get_clipped_raster:414 - Retrieving clipped raster file /home/jace/.geowrangler/nightlights/clip/736d0303579e70d5160f88bbb93f4986.tifCPU times: user 52.6 s, sys: 25.4 s, total: 1min 17s
Wall time: 1min 18s# Save raw features, can be used for validation
raw_features = features[[col for col in features.columns if "_scaled" not in col]]
# Then keep only scaled columns
features = features[[col for col in features.columns if "_scaled" in col]]Inspect the generated features
features.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 22133 entries, 0 to 22132
Data columns (total 61 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 poi_count_scaled 22133 non-null float64
1 atm_count_scaled 22133 non-null float64
2 atm_nearest_scaled 22133 non-null float64
3 bank_count_scaled 22133 non-null float64
4 bank_nearest_scaled 22133 non-null float64
5 bus_station_count_scaled 22133 non-null float64
6 bus_station_nearest_scaled 22133 non-null float64
7 cafe_count_scaled 22133 non-null float64
8 cafe_nearest_scaled 22133 non-null float64
9 charging_station_count_scaled 22133 non-null float64
10 charging_station_nearest_scaled 22133 non-null float64
11 courthouse_count_scaled 22133 non-null float64
12 courthouse_nearest_scaled 22133 non-null float64
13 dentist_count_scaled 22133 non-null float64
14 dentist_nearest_scaled 22133 non-null float64
15 fast_food_count_scaled 22133 non-null float64
16 fast_food_nearest_scaled 22133 non-null float64
17 fire_station_count_scaled 22133 non-null float64
18 fire_station_nearest_scaled 22133 non-null float64
19 food_court_count_scaled 22133 non-null float64
20 food_court_nearest_scaled 22133 non-null float64
21 fuel_count_scaled 22133 non-null float64
22 fuel_nearest_scaled 22133 non-null float64
23 hospital_count_scaled 22133 non-null float64
24 hospital_nearest_scaled 22133 non-null float64
25 library_count_scaled 22133 non-null float64
26 library_nearest_scaled 22133 non-null float64
27 marketplace_count_scaled 22133 non-null float64
28 marketplace_nearest_scaled 22133 non-null float64
29 pharmacy_count_scaled 22133 non-null float64
30 pharmacy_nearest_scaled 22133 non-null float64
31 police_count_scaled 22133 non-null float64
32 police_nearest_scaled 22133 non-null float64
33 post_box_count_scaled 22133 non-null float64
34 post_box_nearest_scaled 22133 non-null float64
35 post_office_count_scaled 22133 non-null float64
36 post_office_nearest_scaled 22133 non-null float64
37 restaurant_count_scaled 22133 non-null float64
38 restaurant_nearest_scaled 22133 non-null float64
39 social_facility_count_scaled 22133 non-null float64
40 social_facility_nearest_scaled 22133 non-null float64
41 supermarket_count_scaled 22133 non-null float64
42 supermarket_nearest_scaled 22133 non-null float64
43 townhall_count_scaled 22133 non-null float64
44 townhall_nearest_scaled 22133 non-null float64
45 road_count_scaled 22133 non-null float64
46 fixed_2019_mean_avg_d_kbps_mean_scaled 22133 non-null float64
47 fixed_2019_mean_avg_u_kbps_mean_scaled 22133 non-null float64
48 fixed_2019_mean_avg_lat_ms_mean_scaled 22133 non-null float64
49 fixed_2019_mean_num_tests_mean_scaled 22133 non-null float64
50 fixed_2019_mean_num_devices_mean_scaled 22133 non-null float64
51 mobile_2019_mean_avg_d_kbps_mean_scaled 22133 non-null float64
52 mobile_2019_mean_avg_u_kbps_mean_scaled 22133 non-null float64
53 mobile_2019_mean_avg_lat_ms_mean_scaled 22133 non-null float64
54 mobile_2019_mean_num_tests_mean_scaled 22133 non-null float64
55 mobile_2019_mean_num_devices_mean_scaled 22133 non-null float64
56 avg_rad_min_scaled 22133 non-null float64
57 avg_rad_max_scaled 22133 non-null float64
58 avg_rad_mean_scaled 22133 non-null float64
59 avg_rad_std_scaled 22133 non-null float64
60 avg_rad_median_scaled 22133 non-null float64
dtypes: float64(61)
memory usage: 11.0 MBRun Model on AOI
Load Model
with open(MODEL_SAVE_PATH, "rb") as f:
model = pickle.load(f)Make Predictions
rollout_aoi["Predicted Relative Wealth Index"] = model.predict(features.values)Binning predictions into wealth categories
Afterwards, we label the predicted relative wealth by binning them into 5 categories: A, B, C, D, and E where A is the highest and E is the lowest.
We can create these wealth categories by splitting the output Predicted Relative Wealth Index distribution into 5 equally sized quintiles, i.e. every 20th percentile.
This categorization may be modified to suit the context of the target country.
rollout_aoi["Predicted Wealth Category (quintile)"] = categorize_wealth_index(
rollout_aoi["Predicted Relative Wealth Index"]
).astype(str)rollout_aoi.info()rollout_aoi.head(2)Save output
%%time
rollout_aoi.to_file(
f"{rollout_date}-{COUNTRY_CODE}-rollout-output.geojson",
driver="GeoJSON",
index=False,
)CPU times: user 3.47 s, sys: 93.8 ms, total: 3.56 s
Wall time: 3.63 s# Join back raw features and save
rollout_output_with_features = rollout_aoi.join(raw_features).join(features)
rollout_output_with_features.to_file(
f"{rollout_date}-{COUNTRY_CODE}-rollout-output-with-features.geojson",
driver="GeoJSON",
index=False,
)Visualizations
Inspect predicted wealth index and output dataframe
rollout_aoi[["Predicted Relative Wealth Index"]].hist()array([[<Axes: title={'center': 'Predicted Relative Wealth Index'}>]],
dtype=object)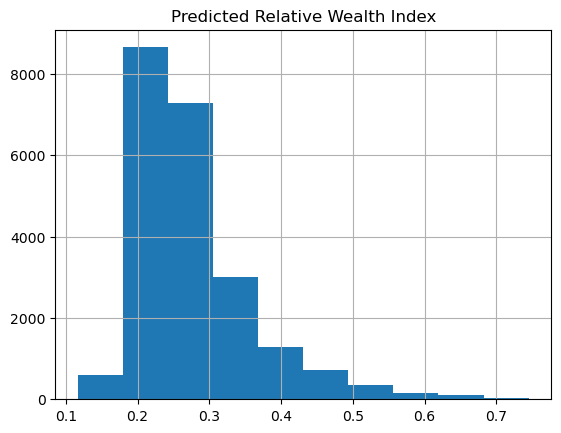
Create Static Maps
Plot Predicted Relative Wealth Index
plt.cla()
plt.clf()
rollout_aoi_plot = rollout_aoi.to_crs("EPSG:3857")
ax = rollout_aoi_plot.plot(
"Predicted Relative Wealth Index",
figsize=(20, 8),
cmap="viridis",
legend=True,
legend_kwds={"shrink": 0.8},
)
cx.add_basemap(ax, source=cx.providers.OpenStreetMap.Mapnik)
ax.set_axis_off()
plt.title("Predicted Relative Wealth Index")
plt.tight_layout()
plt.savefig(f"{rollout_date}-{COUNTRY_CODE}-predicted-wealth-index.png")
plt.show()<Figure size 640x480 with 0 Axes>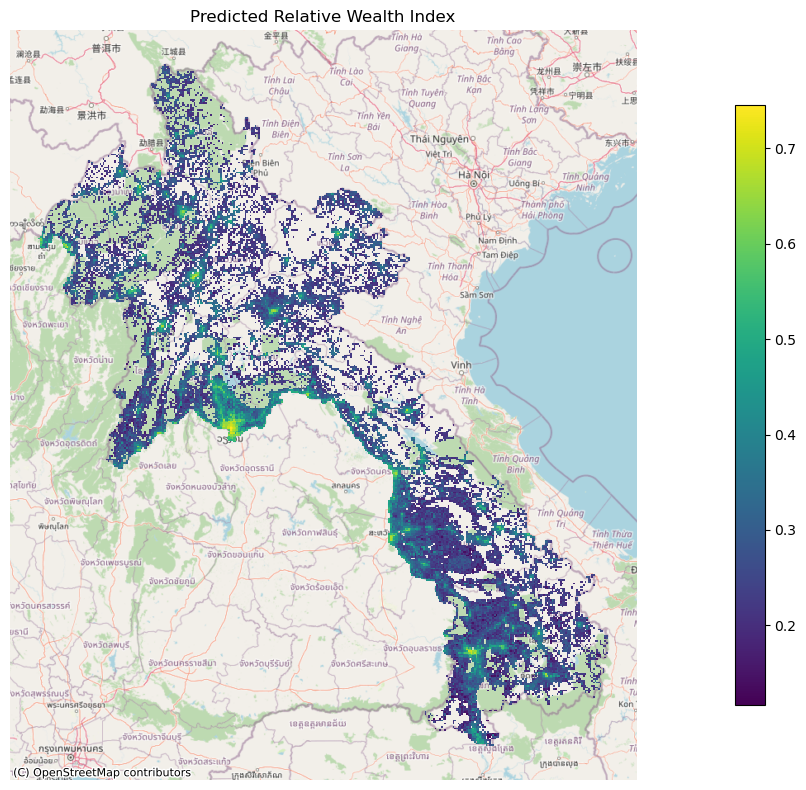
Plot Predicted Relative Wealth Index Category
plt.cla()
plt.clf()
rollout_aoi_plot = rollout_aoi.to_crs("EPSG:3857")
ax = rollout_aoi_plot.plot(
"Predicted Wealth Category (quintile)",
figsize=(20, 8),
cmap="viridis_r",
legend=True,
)
cx.add_basemap(ax, source=cx.providers.OpenStreetMap.Mapnik)
ax.set_axis_off()
plt.title("Predicted Wealth Category")
plt.tight_layout()
plt.savefig(f"{rollout_date}-{COUNTRY_CODE}-predicted-wealth-bin.png")
plt.show()<Figure size 640x480 with 0 Axes>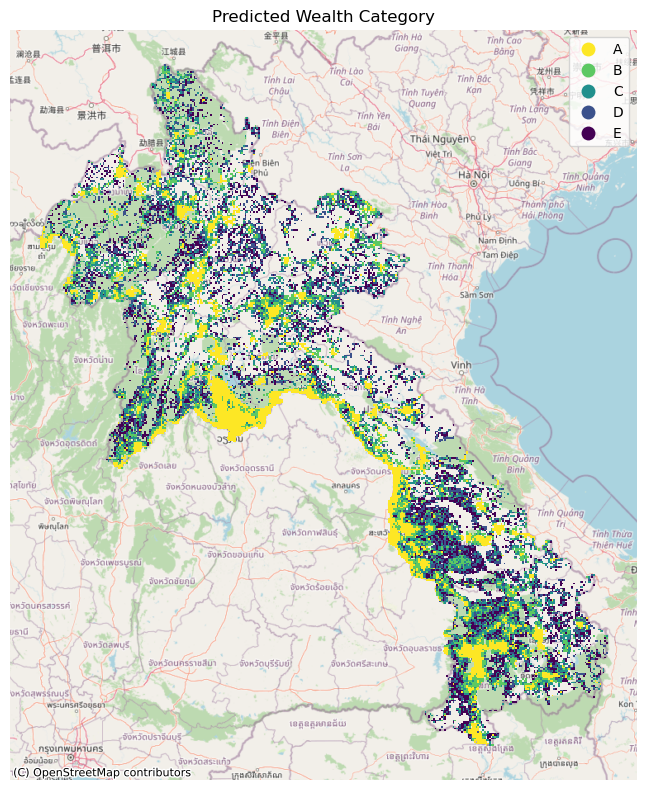
Create an Interactive Map
cols_of_interest = [
"quadkey",
"shapeName",
"shapeGroup",
"pop_count",
"avg_rad_mean",
"mobile_2019_mean_avg_d_kbps_mean",
"fixed_2019_mean_avg_d_kbps_mean",
"poi_count",
"road_count",
"Predicted Relative Wealth Index",
"Predicted Wealth Category (quintile)",
]
# Warning: This can be a bit laggy due to the large amount of tiles being visualized
# Uncomment the ff if you want to viz the raw wealth predictions
# rollout_aoi.explore(column='Predicted Relative Wealth Index', tooltip=cols_of_interest, cmap="viridis")
# Uncomment the ff if you want to view the quintiles
# rollout_aoi.explore(column='Predicted Wealth Category (quintile)', tooltip=cols_of_interest, cmap="viridis_r")Alternatively, you may also try to visualize this interactively in Kepler by uploading the rollout output geojson file.