/home/jc_tm/project_repos/unicef-ai4d-poverty-mapping/env/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%reload_ext autoreload%autoreload 2
Experiment Details
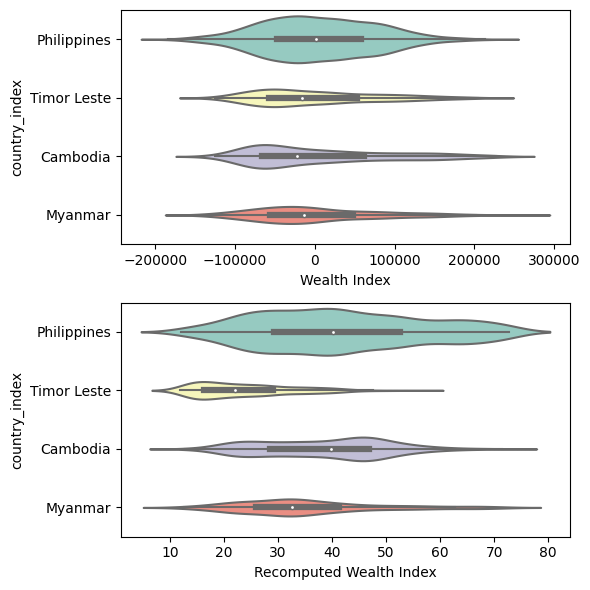
In this notebook, we will try to run a regression model on recalculated wealth indices to account for differences between countries
Set up Data Access
# Instantiate data managers for Ookla and OSM# This auto-caches requested data in RAM, so next fetches of the data are faster.osm_data_manager = OsmDataManager(cache_dir=settings.ROOT_DIR/"data/data_cache")ookla_data_manager = OoklaDataManager(cache_dir=settings.ROOT_DIR/"data/data_cache")dhs_data_manager = DHSDataManager()
# Log-in using EOG credentialsusername = os.environ.get('EOG_USER',None)username = username if username isnotNoneelseinput('Username?')password = os.environ.get('EOG_PASSWORD',None)password = password if password isnotNoneelse getpass.getpass('Password?') # set save_token to True so that access token gets stored in ~/.eog_creds/eog_access_tokenaccess_token = nightlights.get_eog_access_token(username,password, save_token=True)
2023-02-06 13:22:02.901 | INFO | povertymapping.nightlights:get_eog_access_token:48 - Saving access_token to ~/.eog_creds/eog_access_token
2023-02-06 13:22:02.903 | INFO | povertymapping.nightlights:get_eog_access_token:56 - Adding access token to environmentt var EOG_ACCESS_TOKEN
This section creates countries_cluster_data (gpd.GeoDataFrame) which combines DHS/Ookla/OSM/VIIRS data for all specified countries.
%%time# Create list of dataframes per country, and list of all columns appearing in DHS columnscountry_cluster_data_list = []dhs_columns = ['DHSCLUST']for country, config in country_config.items():print(f'Loading data for {country}')# Load the DHS cluster data dhs_household_dta_path = config['dhs_household_dta_path'] dhs_geographic_shp_path = config['dhs_geographic_shp_path'] country_code = config['country_code'] dhs_gdf = dhs_data_manager.generate_dhs_cluster_level_data( country, dhs_household_dta_path, dhs_geographic_shp_path, col_rename_config=country_code, convert_geoms_to_bbox=True, bbox_size_km =2.4, overwrite_cache=True ).reset_index(drop=True) dhs_columns =list(set(dhs_columns +list(dhs_gdf.columns)))# Generate base features for the dhs dataframe country_cluster_data = dhs_gdf.copy() country_osm = config['country_osm'] ookla_year = config['ookla_year'] nightlights_year = config['nightlights_year']# Add in OSM features country_cluster_data = osm.add_osm_poi_features(country_cluster_data, country_osm, osm_data_manager) country_cluster_data = osm.add_osm_road_features(country_cluster_data, country_osm, osm_data_manager)# Add in Ookla features country_cluster_data = ookla.add_ookla_features(country_cluster_data, 'fixed', ookla_year, ookla_data_manager) country_cluster_data = ookla.add_ookla_features(country_cluster_data, 'mobile', ookla_year, ookla_data_manager)# Add in the nighttime lights features country_cluster_data = nightlights.generate_nightlights_feature(country_cluster_data, nightlights_year) country_cluster_data_list.append(country_cluster_data)# Combine all country data into a single dataframecountries_cluster_data = gpd.GeoDataFrame(pd.concat(country_cluster_data_list,ignore_index=True), crs=country_cluster_data_list[0].crs)
Loading data for Philippines
Overwriting Philippines in cache
2023-02-06 13:32:21.835 | DEBUG | povertymapping.osm:load_pois:139 - OSM POIs for philippines found in cache.
Overwriting Philippines in cache
2023-02-06 13:32:26.132 | DEBUG | povertymapping.osm:load_roads:158 - OSM Roads for philippines found in cache.
2023-02-06 13:32:29.550 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:32:29.552 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, fixed 2019 (key: 2f858b388182d50703550c8ef9d321df) found in cache.
2023-02-06 13:32:30.858 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:32:30.860 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, mobile 2019 (key: 5a45dc45080a935951e6c2b6c0052b13) found in cache.
2023-02-06 13:32:33.057 | INFO | povertymapping.nightlights:get_clipped_raster:414 - Retrieving clipped raster file /home/jc_tm/.geowrangler/nightlights/clip/295bf47ce6753c7f06ab79012b769f2a.tif
Loading data for Timor Leste
2023-02-06 13:32:52.781 | DEBUG | povertymapping.osm:load_pois:139 - OSM POIs for east-timor found in cache.
Overwriting Timor Leste in cache
Overwriting Timor Leste in cache
2023-02-06 13:32:54.230 | DEBUG | povertymapping.osm:load_roads:158 - OSM Roads for east-timor found in cache.
2023-02-06 13:32:54.315 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:32:54.316 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, fixed 2019 (key: 206a0323fa0e80f82339b66d0c859b4a) found in cache.
2023-02-06 13:32:54.421 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:32:54.422 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, mobile 2019 (key: 209c2544788b8e2bdf4db4685c50e26d) found in cache.
2023-02-06 13:32:54.549 | INFO | povertymapping.nightlights:get_clipped_raster:414 - Retrieving clipped raster file /home/jc_tm/.geowrangler/nightlights/clip/b0d0551dd5a67c8eada595334f2655ed.tif
Loading data for Cambodia
2023-02-06 13:33:01.196 | DEBUG | povertymapping.osm:load_pois:139 - OSM POIs for cambodia found in cache.
Overwriting Cambodia in cache
Overwriting Cambodia in cache
2023-02-06 13:33:02.679 | DEBUG | povertymapping.osm:load_roads:158 - OSM Roads for cambodia found in cache.
2023-02-06 13:33:03.002 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:33:03.003 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, fixed 2019 (key: 37f570ebc130cb44f9dba877fbda74e2) found in cache.
2023-02-06 13:33:03.240 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:33:03.241 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, mobile 2019 (key: 1128a917060f7bb88c0a6260ed457091) found in cache.
2023-02-06 13:33:03.465 | INFO | povertymapping.nightlights:get_clipped_raster:414 - Retrieving clipped raster file /home/jc_tm/.geowrangler/nightlights/clip/4791e78094ba7e323fd5814b3f094a84.tif
Loading data for Myanmar
2023-02-06 13:33:11.654 | DEBUG | povertymapping.osm:load_pois:139 - OSM POIs for myanmar found in cache.
Overwriting Myanmar in cache
Overwriting Myanmar in cache
2023-02-06 13:33:13.186 | DEBUG | povertymapping.osm:load_roads:158 - OSM Roads for myanmar found in cache.
2023-02-06 13:33:13.579 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:33:13.579 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, fixed 2019 (key: d72ec7e4d144b750e1c0950ecad081e0) found in cache.
2023-02-06 13:33:13.747 | DEBUG | povertymapping.ookla:load_type_year_data:68 - Contents of data cache: ['2f858b388182d50703550c8ef9d321df', '5a45dc45080a935951e6c2b6c0052b13', '206a0323fa0e80f82339b66d0c859b4a', '209c2544788b8e2bdf4db4685c50e26d', '37f570ebc130cb44f9dba877fbda74e2', '1128a917060f7bb88c0a6260ed457091', 'd72ec7e4d144b750e1c0950ecad081e0', '2aff65fdf8072457cba0d42873b7a9c2']
2023-02-06 13:33:13.748 | DEBUG | povertymapping.ookla:load_type_year_data:70 - Ookla data for aoi, mobile 2019 (key: 2aff65fdf8072457cba0d42873b7a9c2) found in cache.
2023-02-06 13:33:13.926 | INFO | povertymapping.nightlights:get_clipped_raster:414 - Retrieving clipped raster file /home/jc_tm/.geowrangler/nightlights/clip/7a58f067614b6685cd9bb62d4d15a249.tif
CPU times: user 1min 12s, sys: 8.22 s, total: 1min 21s
Wall time: 1min 21s
# Explore as a map with first 30 columns in tooltipcountries_cluster_data.iloc[:, :30].explore()
Make this Notebook Trusted to load map: File -> Trust Notebook
Data Preparation
Hotfix for Cambodia
For the Cambodia data specifically, the drinking water column in the base files is actually separated by wet and dry season. We’ll edit the cached data to add a “drinking water” column as the mean of the dry/wet columns
dhs_kh_household_temp = dhs_data_manager.household_data["Cambodia"].copy()dhs_kh_household_temp[['drinking water', 'source of drinking water during the dry season', 'source of drinking water during wet season']]
drinking water
source of drinking water during the dry season
source of drinking water during wet season
0
NaN
43.0
51.0
1
NaN
43.0
43.0
2
NaN
51.0
51.0
3
NaN
51.0
51.0
4
NaN
43.0
51.0
...
...
...
...
15820
NaN
43.0
31.0
15821
NaN
31.0
31.0
15822
NaN
32.0
32.0
15823
NaN
32.0
32.0
15824
NaN
43.0
51.0
15825 rows × 3 columns
dhs_data_manager.household_data["Cambodia"]["drinking water"] = dhs_kh_household_temp[['source of drinking water during the dry season', 'source of drinking water during wet season']].mean(axis=1)dhs_data_manager.household_data["Cambodia"]["drinking water"]
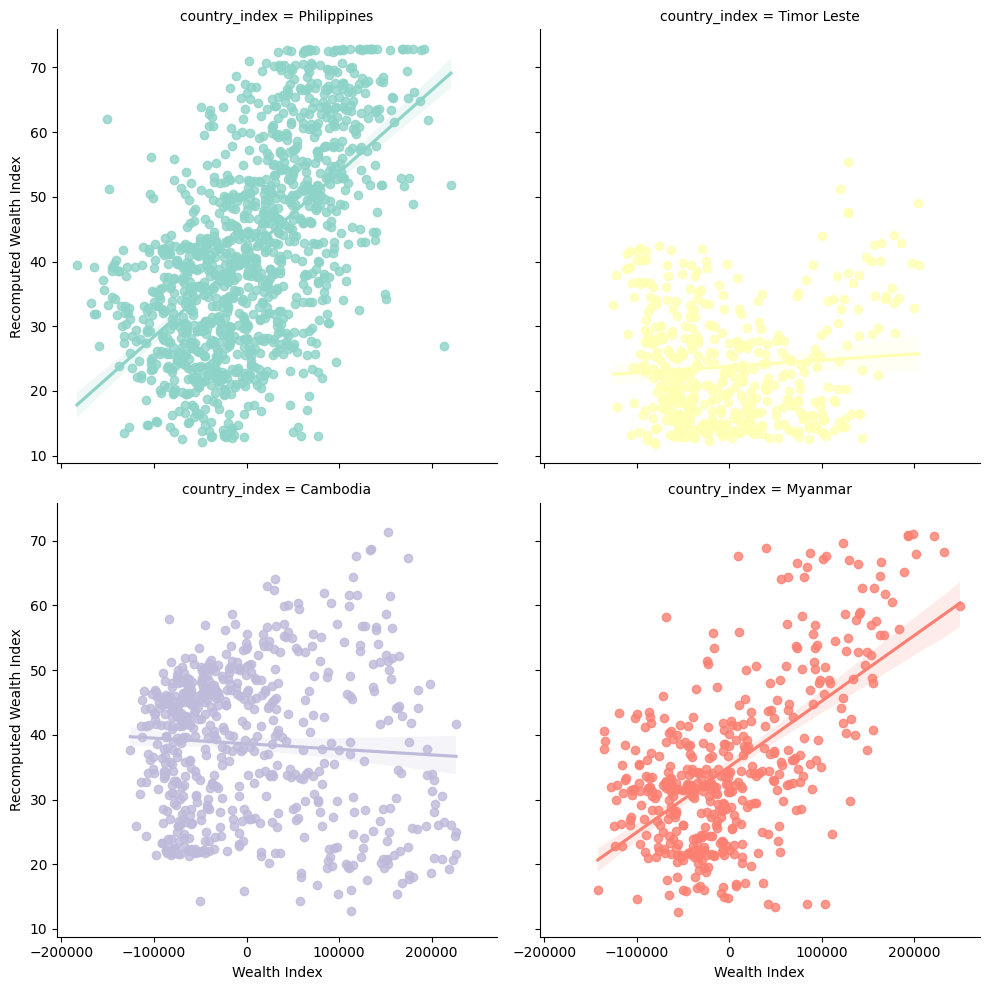
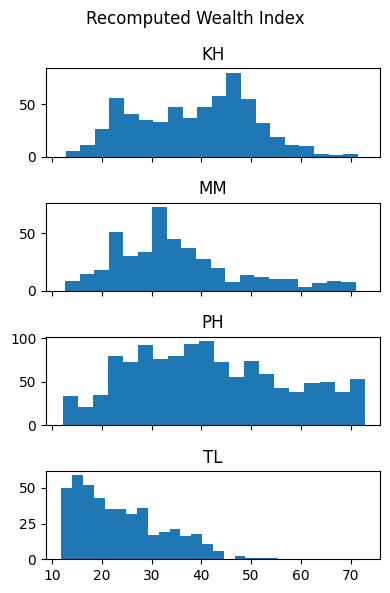
After loading the DHS data using the DHSDataManager class, we can then run recompute_index_cluster_level to get the recomputed wealth index, pooling together data for all countries specified.
features = ["rooms","electric","mobile telephone","radio","television","car/truck","refrigerator","motorcycle","floor","toilet","drinking water",]
# Get country list from country_config's keyscountries =list(country_config.keys())recomputed_index_df = dhs_data_manager.recompute_index_cluster_level(countries, index_features=features)recomputed_index_df = recomputed_index_df[['DHSID', 'country_index', 'Wealth Index', 'Recomputed Wealth Index']]recomputed_index_df.info()
Combining household data for the ff. countries: ['Philippines', 'Timor Leste', 'Cambodia', 'Myanmar']
Combining cluster data for the ff. countries: ['Philippines', 'Timor Leste', 'Cambodia', 'Myanmar']
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2720 entries, 0 to 2719
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 DHSID 2720 non-null object
1 country_index 2720 non-null object
2 Wealth Index 2720 non-null float64
3 Recomputed Wealth Index 2720 non-null float64
dtypes: float64(2), object(2)
memory usage: 106.2+ KB
## Join the wealth index to countries_cluster_datacountries_pooled_index_data = countries_cluster_data.merge(recomputed_index_df[['DHSID', 'Recomputed Wealth Index']], on='DHSID')
# Split train/test data into features and labels# For labels, we just select the target label columnlabels = countries_pooled_index_data[[label_col]]# For features, drop all columns from the input dhs files# If you need the cluster data, refer to country_data / country_testfeatures = countries_pooled_index_data.drop(dhs_columns + ['Recomputed Wealth Index'], axis=1)features.shape, labels.shape
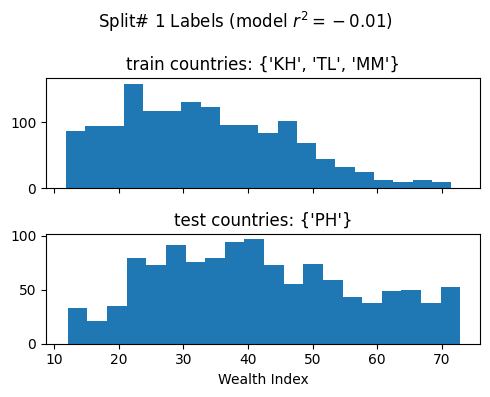
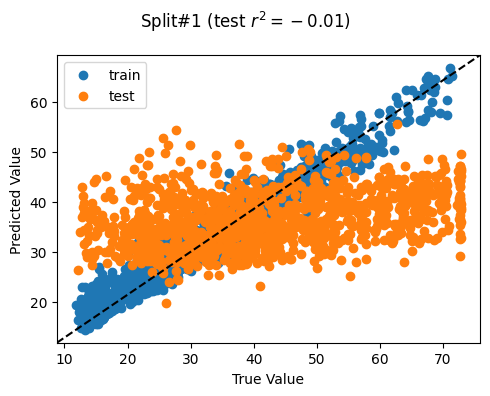
# train_features, test_features, train_labels, test_labels = train_test_split(# features, labels, test_size=test_size, random_state=train_test_seed# )# Cross validationprint(f"Performing GroupKFold CV with groups based on DHSCC...")groups = countries_pooled_index_data[groupkfold_col].valuescv = GroupKFold(n_splits =len(set(groups)))print(cv.split(features, groups=groups))print(f'Number of splits based on DHSCC unique values: {cv.get_n_splits()}')
Performing GroupKFold CV with groups based on DHSCC...
<generator object _BaseKFold.split at 0x7f2564373eb0>
Number of splits based on DHSCC unique values: 4
Instantiate model
For now, we will train a simple random forest model
from sklearn.ensemble import RandomForestRegressormodel = RandomForestRegressor(n_estimators=100, random_state=train_test_seed, verbose=0)model
RandomForestRegressor(random_state=42)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor(random_state=42)
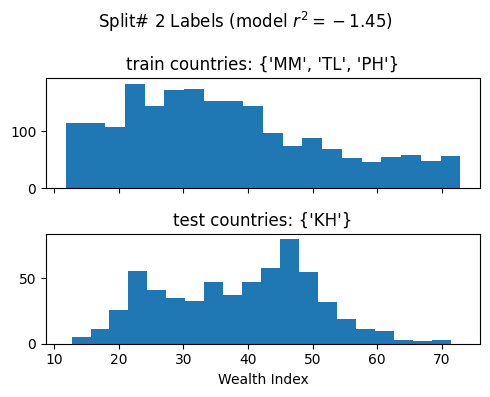
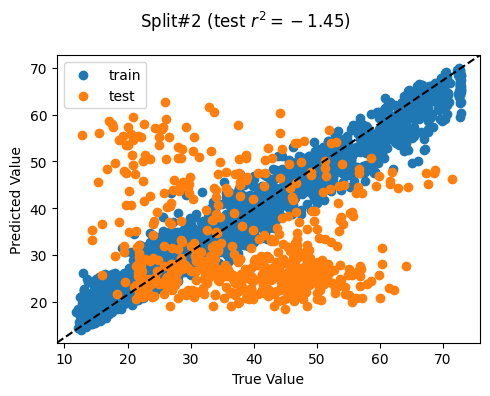
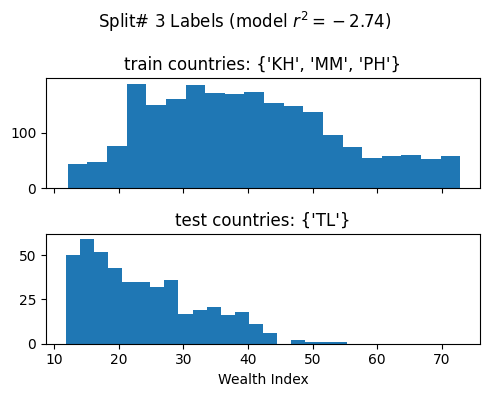
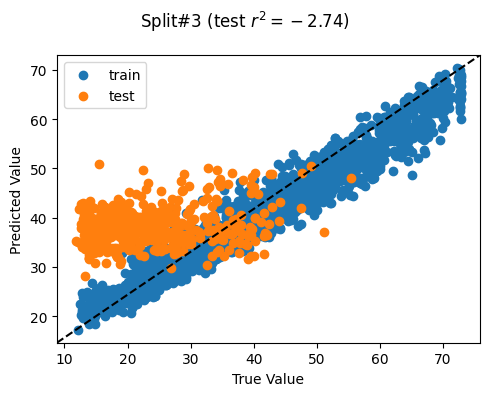
Evaluate model training using cross-validation
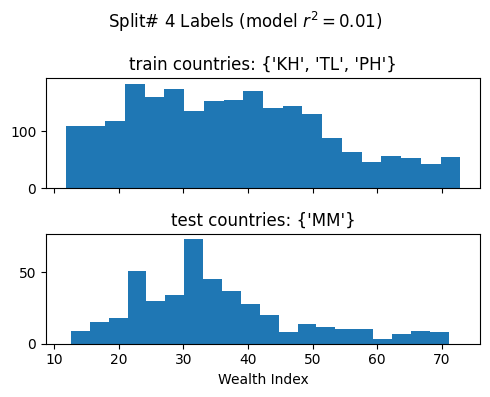
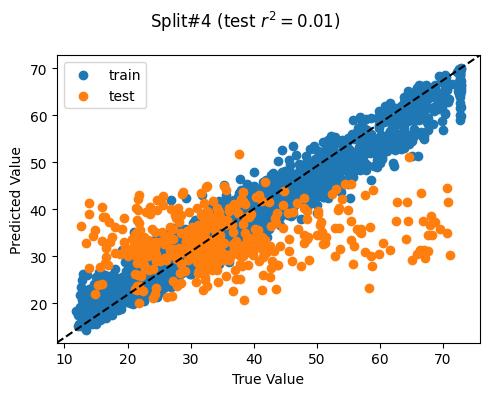
We evalute the model’s generalizability when training over different train/test splits
Ideally for R^2
We want a high mean: This means that we achieve a high model performance over the different train/test splits
We want a low standard deviation (std): This means that the model performance is stable over multiple training repetitions