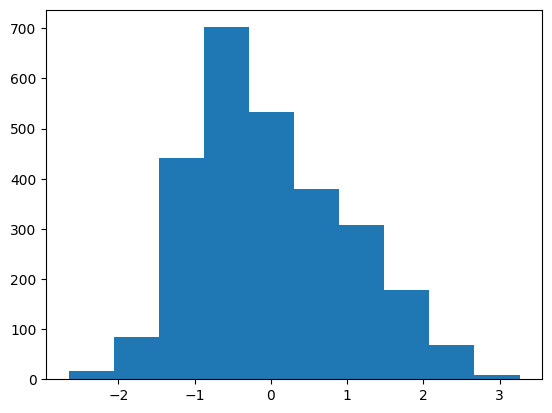
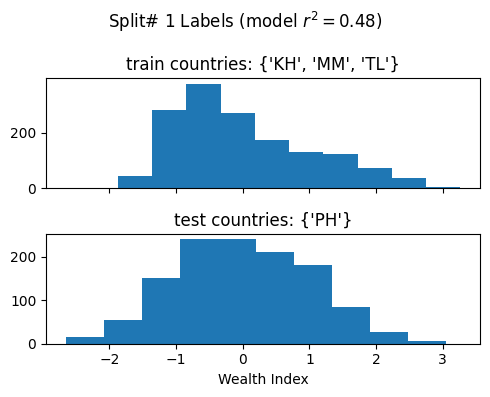
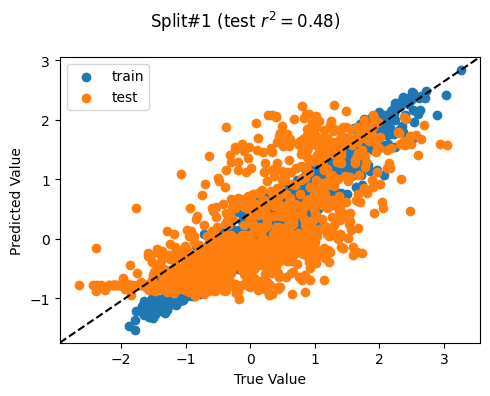
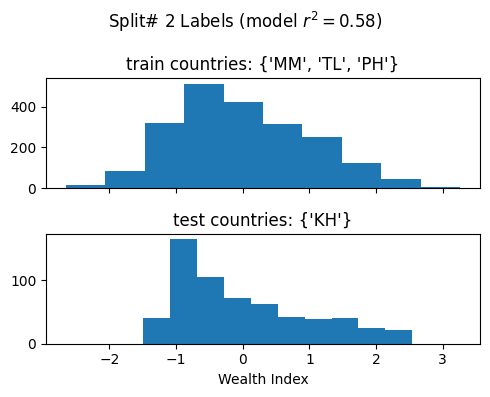
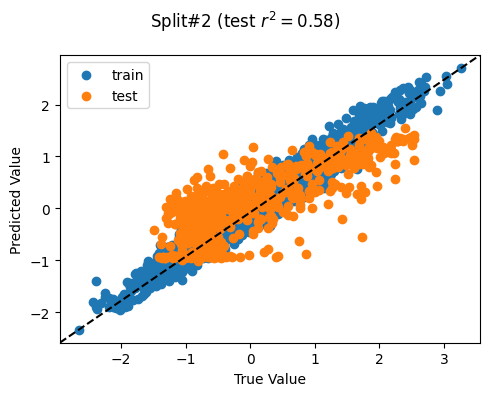
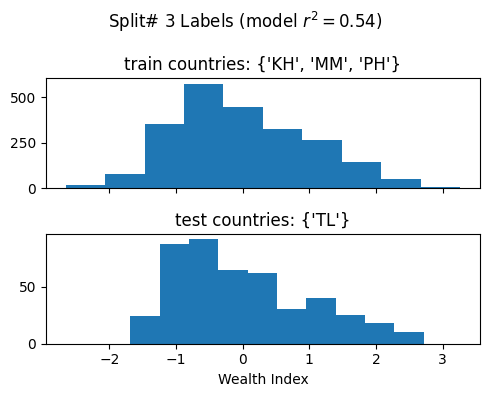
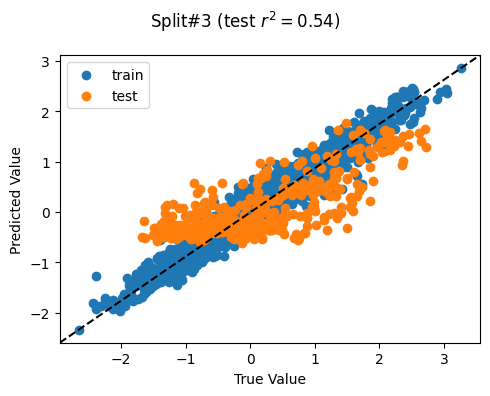
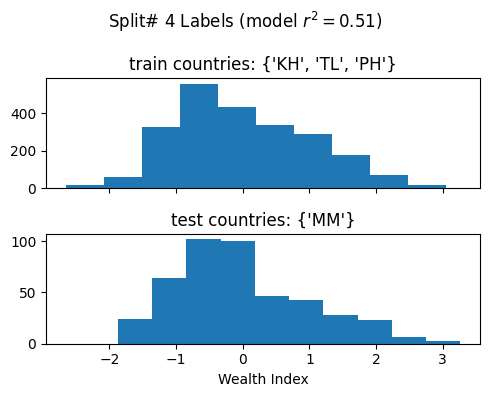
['poi_count', 'atm_count', 'atm_nearest', 'bank_count', 'bank_nearest', 'bus_station_count', 'bus_station_nearest', 'cafe_count', 'cafe_nearest', 'charging_station_count', 'charging_station_nearest', 'courthouse_count', 'courthouse_nearest', 'dentist_count', 'dentist_nearest', 'fast_food_count', 'fast_food_nearest', 'fire_station_count', 'fire_station_nearest', 'food_court_count', 'food_court_nearest', 'fuel_count', 'fuel_nearest', 'hospital_count', 'hospital_nearest', 'library_count', 'library_nearest', 'marketplace_count', 'marketplace_nearest', 'pharmacy_count', 'pharmacy_nearest', 'police_count', 'police_nearest', 'post_box_count', 'post_box_nearest', 'post_office_count', 'post_office_nearest', 'restaurant_count', 'restaurant_nearest', 'social_facility_count', 'social_facility_nearest', 'supermarket_count', 'supermarket_nearest', 'townhall_count', 'townhall_nearest', 'road_count', 'fixed_2019_mean_avg_d_kbps_mean', 'fixed_2019_mean_avg_u_kbps_mean', 'fixed_2019_mean_avg_lat_ms_mean', 'fixed_2019_mean_num_tests_mean', 'fixed_2019_mean_num_devices_mean', 'mobile_2019_mean_avg_d_kbps_mean', 'mobile_2019_mean_avg_u_kbps_mean', 'mobile_2019_mean_avg_lat_ms_mean', 'mobile_2019_mean_num_tests_mean', 'mobile_2019_mean_num_devices_mean', 'avg_rad_min', 'avg_rad_max', 'avg_rad_mean', 'avg_rad_std', 'avg_rad_median']