import osimport sys"../../../" )import jsonimport pickleimport fasttreeshapimport numpy as npimport pandas as pdimport shapfrom sklearn.model_selection import RepeatedKFold, cross_val_score% reload_ext autoreload% autoreload 2
IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
Load Training Data
= "kh" = "-" .join(os.getcwd().split("/" )[- 2 ].split("-" )[:3 ])# CSV file contains all data # Metadata JSON file lists the feature columns and label column = pd.read_csv(f" { ROLLOUT_DATE} -training-data.csv" )with open (f" { ROLLOUT_DATE} -training-data-columns.json" , "r" ) as file := json.load(file )= data[column_metadata["features" ]]= data[column_metadata["label" ]]
Cross-Validation
# Set parameters = 5 = 5 = 42
print (f"Performing { CV_K_FOLDS} -fold CV..." )= RepeatedKFold(= CV_K_FOLDS,= CV_NUM_REPEATS,= RANDOM_SEED,print (cv.split(features))
Performing 5-fold CV...
<generator object _RepeatedSplits.split at 0x7fde9a348dd0>
from sklearn.ensemble import RandomForestRegressor= RandomForestRegressor(n_estimators= 100 , random_state= RANDOM_SEED, verbose= 0 )= cross_val_score(model, features.values, labels.values.ravel(), cv= cv)= round (np.array(R_cv).mean(), 2 )= round (np.array(R_cv).std(), 2 )print ("Cross validation scores are: " , R_cv)print (f"Cross validation R^2 mean: { cv_mean} " )print (f"Cross validation R^2 std: { cv_std} " )
Cross validation scores are: [0.76378081 0.56180401 0.64007075 0.75678818 0.75580597 0.71565578
0.65857361 0.71083648 0.64518727 0.79671673 0.74850064 0.73351956
0.72262599 0.70720609 0.68441362 0.69442655 0.7988868 0.67577956
0.66425548 0.71572513 0.65445565 0.64187833 0.76528128 0.74395808
0.75334561]
Cross validation R^2 mean: 0.71
Cross validation R^2 std: 0.06
Train the final model
For training the final model, we train on all the available data.
= RandomForestRegressor(n_estimators= 100 , random_state= RANDOM_SEED, verbose= 0 )
RandomForestRegressor(random_state=42) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
= f"./ { ROLLOUT_DATE} - { COUNTRY_CODE} -single-country-model.pkl" with open (model_save_path, "wb" ) as file :file )
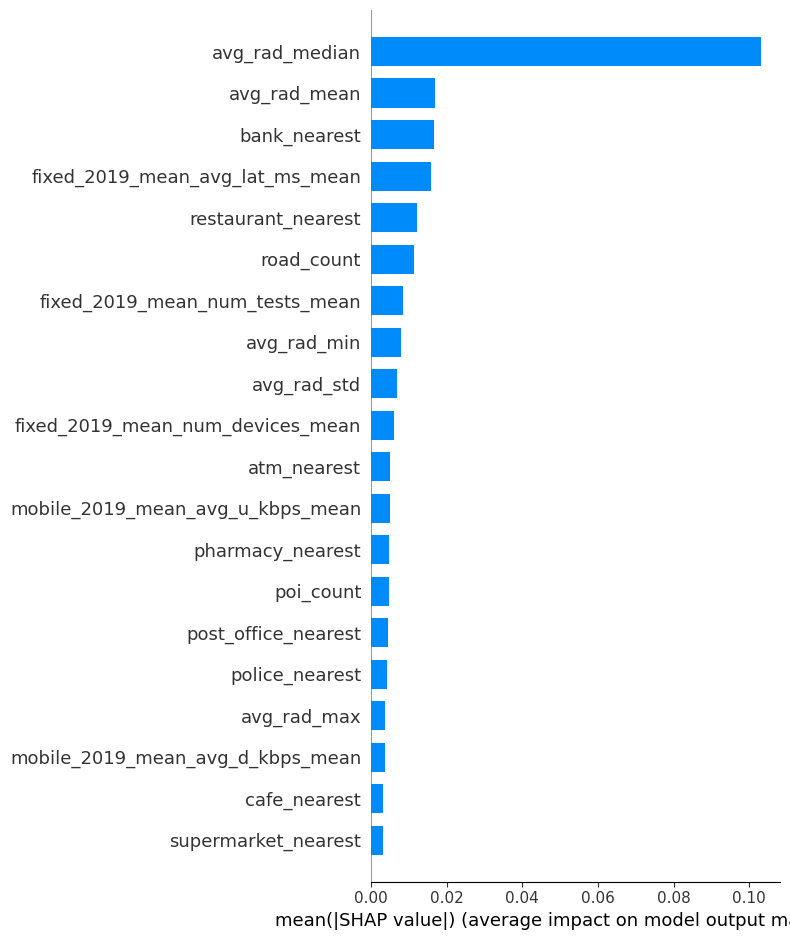
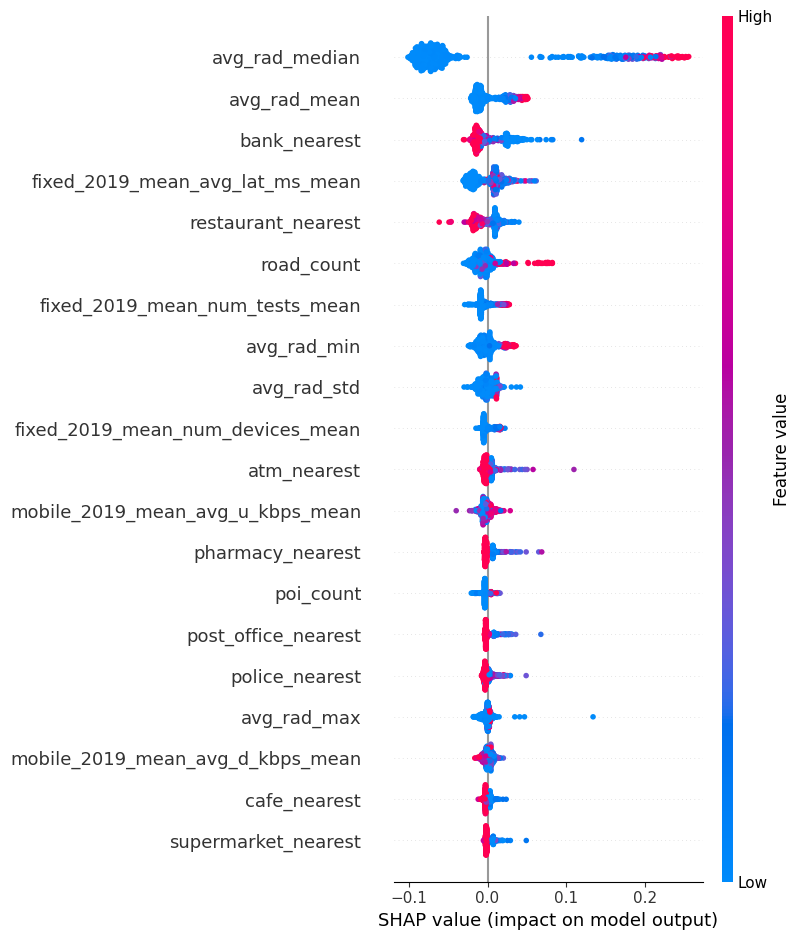
SHAP
= fasttreeshap.TreeExplainer(model, algorithm= "auto" , n_jobs=- 1 )= explainer(features).values
= features.columns, plot_type= "bar"
= features.columns)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored